
Saviez-vous que le système de fichiers ext4 semble plus rapide en lecture lorsque les droits des fichiers sont en chmod 444 (lecture seule) plutôt qu’en lecture-écriture ? Le point sur cet étrange phénomène à exploiter au quotidien pour connaître son système de fichiers et optimiser les performances de serveurs et postes de travail. D’ailleurs je me demande toujours si cela est propre à ext4 ou plutôt à la manière dont Linux utilise les droits, quelque soit le système de fichiers utilisé.
Un étrange phénomène
Un beau matin il m’a fallu sécuriser un site internet afin de réduire les failles au minimum et ne pas prêter le flanc trop facilement aux scripts-kiddies ou autres techniques pirates, qui peuvent défacer le contenu ou bien spammer le site et nuire durablement au référencement.
Naturellement, et cela fera l’objet d’un article dédié, je suis passé par la limitation au maximum des fichiers hébergés afin d’interdire les droits d’écriture aux scripts PHP qui n’ont besoin que d’être lus pour êtres par le préprocesseur pour être interprétés.
Ceci fait, j’ai eu comme l’impression que le site internet était plus réactif lors de la navigation. Cela m’a paru très étonnant, et je me suis penché sur les causes de ce gain en rapidité. Après quelques tests rapides j’ai pu mettre en évidence que sous ext4, la performance en lecture d’un petit fichier dépend notamment des droits qui lui sont associés. A voir si cela est généralisable à d’autres systèmes de fichiers.
Faire des découvertes sur le fonctionnement de base de son système de fichiers Linux n’est pas si courant, et c’est plutôt sympa à partager. Si vous êtes méfiant sur ce que j’annonce, comme je l’étais moi-même, je vous invite à effectuer la procédure de benchmarking sur votre ordinateur.

Attention, ce qui suit n’est pas un guide d’optimisation de ext4 mais plutôt une tentative de documentation d’un fait surprenant qui joue de quelques pourcents sur la vitesse de lecture de petits fichiers. Il existe de nombreux paramètres du système de fichiers qui influent beaucoup plus sur les performances pour votre cas de figure précis. Pour en citer quelques uns : le scheduler (deadline, noop, cfq, anticipatory), le délai avant écriture disque (commit time), les paramètres de montage (noatime, nodiratime), la taille du cluster (cluster size).
La mise en évidence des différences de performances
Le script de benchmarking
Voici le script de benchmarking qui effectue automatiquement les opérations suivantes :
- Création de 4 * 10 fichiers de 100 Ko pour tester quatre séries de dix échantillons.
- Mise en œuvre des chmod de droits de fichier 444, 555, 666 et 777 soit respectivement r–, r-x, rw-, rwx.
- Lecture de ce fichier en utilisant deux protocoles de test : md5sum qui est un programme de hash qui doit par définition lire le fichier du début à la fin, et dd qui est un outil de traitement de données brutes sous GNU/Linux, et qui est ici utilisé pour lire le fichier (et rediriger le tout dans le néant de /dev/null).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#!/bin/bash # Création de trois fichiers aléatoires différents pour trois cas de figure (r-- ; r-x ; rw- ; rwx) for i in "r--" "r-x" "rw-" "rwx" do for j in $(seq -w 0 1 9) do dd if=/dev/urandom of=${i}_${j} bs=10K count=1 &> /dev/null done done # Application des droits de fichier chmod 444 r--* chmod 555 r-x* chmod 666 rw-* chmod 777 rwx* # Opérations de lecture : md5sum (checksum) et dd (lecture simple) for i in $(ls r??_?) do sync; echo 3 > /proc/sys/vm/drop_caches tic=$(date +%S.%N) md5sum $i >/dev/null tac=$(date +%S.%N) echo $(bc <<< $tac-$tic) > ${i}.md5.time sync; echo 3 > /proc/sys/vm/drop_caches tic=$(date +%S.%N) dd if=$i of=/dev/null &> /dev/null tac=$(date +%S.%N) echo $(bc <<< $tac-$tic) > ${i}.dd.time done ls r??_? > ls.txt cat r??_?.md5.time > md5.txt cat r??_?.dd.time > dd.txt echo "fichier md5 dd" >stats.txt paste ls.txt md5.txt dd.txt >>stats.txt # Nettoyage rm *.md5.time *.dd.time r??_? rm ls.txt md5.txt dd.txt |
Les tests sont réalisés sous Ubuntu 14.04LTS avec un noyau Linux 3.13.0-44. Le système de fichiers racine ext4 est monté avec les options defaults dans fstab et le disque dur est un Velociraptor qui tourne à 10 000tr/min. Question processeur, c’est un AMD Athlon FX-8350. L’utilisateur officiel des fichiers n’a pas d’importance puisque les droits sont les mêmes pour user, group et others.
On obtient en sortie un fichier stats.txt qui récapitule les temps de lecture des fichiers sous forme d’un tableau.
|
1 2 3 4 5 |
fichier md5 dd r--_0 .003023676 .003343198 r--_1 .003527038 .003643472 r--_2 .004295804 .003599478 [...] |
Le graphe attendu
Ce fichier se transforme en CSV facilement en remplaçant les tabulations en point-virgule. Voici les résultats synthétiques des tests, avec la moyenne des 10 échantillons pour les quatre séries. Si on s’amuse à calculer l’écart type sur chaque série, on constate qu’il est très proche de zéro ce qui indique que la répétabilité du test est excellente sans qu’il y ait de valeur absurde et très différente des autres. La première vague de tests de lecture est réalisée avec md5sum, et on peut penser que le système d’exploitation aura mis une partie des données dans le cache de fichiers pour la seconde de vague de tests avec dd. Cela ne devrait pas être gênant pour comparer les données de md5sum entre elles et les données de dd entre elles, mais par précaution on vide le cache avant chaque lecture.
|
1 2 3 4 5 |
droit md5 (moyenne) dd (moyenne) r-- 0,003745152 0,003714936 rw- 0,0039409 0,004119141 r-x 0,00396792 0,004147965 rwx 0,004208753 0,004192675 |
En lisant ces données, le premier réflexe est de croire que tout tient dans un mouchoir de poche et qu’il n’y a pas de différence notable entre tous ces temps de lecture. Sur cet échantillon de données, la lecture du fichier est plus rapide en lecture seule plutôt qu’en lecture-écriture-exécution, avec un gain de 12%.
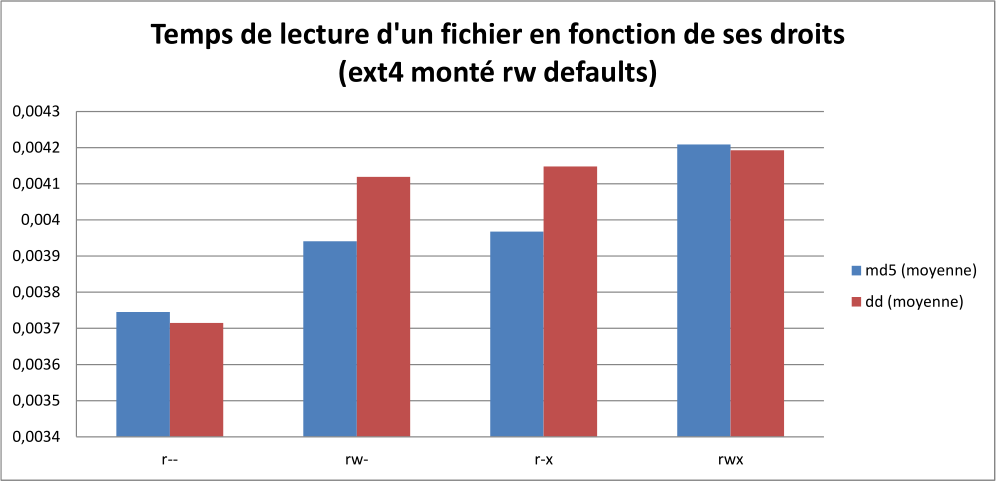
Pour un système informatique utilisé au quotidien, un tel écart de performances est significatif et toujours le bienvenu. Néanmoins ce chiffre n’est pas à prendre au pied de la lettre car en multipliant les essais je trouve des variations ; si le r– reste le plus rapide et le rwx le plus lent, le gain se plutôt entre 5% et 12%.
Et pour d’autres systèmes de fichiers ?
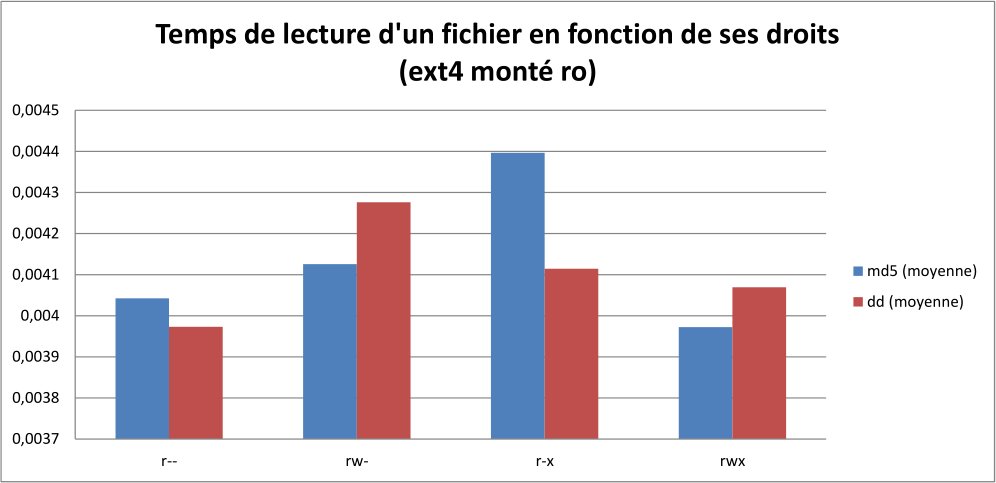
Ext4 monté en lecture seule
Pour cette variante du benchmark, on utilise le script ci-dessus pour créer les fichiers aléatoires de 100 Ko, puis on remonte le système de fichiers en lecture seule grâce à la commande suivante. Les fichiers de sortie texte sont stockés dans un répertoire temporaire puisque le répertoire ./ est en lecture seule.
|
1 |
mount -o remount,ro /point/de/montage |
Les écarts de performance diminuent à moins de 10% entre le chmod le plus rapide et le plus lent, et le droit d’écriture semble très curieusement avoir une incidence sur la vitesse de lecture du fichier. Mis à part cela, je ne sais pas vraiment expliquer ces résultats. Par manque de temps j’en resterai là, d’autant plus que je monte par couramment mes partitions en ro.
Sur un SSD
Un test réalisé sur un SSD a montré que toutes les valeurs sont identiques quelque soient les droits des fichiers. Il est possible que les écarts de valeurs dépendent de la mécanique du disque dur et de son firmware.
Les applications concrètes à en tirer
- L’hébergement de sites internet : quand en sait qu’une installation wordpress toute neuve compte environ 1700 fichiers pour une moyenne autour de 14 Ko, on imagine bien que le gain en lecture obtenu sur chacun peut être perceptible par l’internaute. Cela sera vrai pour la première visite, puisque normalement le serveur web doit mettre en cache de fichiers (en mémoire) les fichiers les plus souvent lus.
- Le serveur de fichiers réseau (samba, nfs, …) : là encore le gain peut théoriquement être perceptible par l’utilisateur, d’autant plus que le serveur n’aura pas toujours la possibilité de mettre tous les fichiers en cache, la quantité de mémoire étant plus limitée que l’espace de stockage global.
- La sécurité du serveur : cet article traite de l’effet de bord induit par les droits des fichiers sur la vitesse de lecture. Mais il ne faut pas oublier qu’à l’origine les droits des fichiers sont une méthode de base du système d’exploitation pour contrôler qui a le droit de modification sur le fichier. En y réfléchissant bien, il existe de nombreux cas où on devrait retirer le droit de modification du fichier, principalement pour sécuriser son système, et éventuellement pour gagner quelques pourcents en performances.
Conclusion
Comme je l’évoquais en introduction de cet article, je n’ai toujours pas découvert si ce phénomène provient en vérité du système de fichiers ou du système d’exploitation. Malgré ma tentative de documentation et de benchmarking, l’approfondissement de ce phénomène mériterait un véritable plan d’expériences à plusieurs dizaines de paramètres pour connaître l’impact réel des droits des fichiers sur la vitesse de lecture. Je n’ai malheureusement pas le temps de mener à bien une telle étude, mais si vous avez des informations sur le sujet vous pouvez m’en faire part.
De plus, je compte vérifier comment cela évolue avec la taille du fichier. Je pressens que le coût des droits des fichiers est fixe, et très faible, si bien qu’il devient insignifiant pour des fichiers supérieurs à 100 ko.